¶ APIs del orquestador
El orquestador, desarrollado por Aire Cloud, cuenta con una completa interfaz de gestión a través de APIs. Estas interfaces permiten integrar sus funcionalidades con otros sistemas, automatizar procesos y optimizar la administración de recursos de forma ágil y eficiente. A continuación en esta página, se detallan tanto las principales APIs disponibles como dónde consultar la documentación sobre ellas, asi como casos de uso y ejemplos comunes a modo de introducción.
¶ Acciones basadas en APIs
Para comprender realmente la importancia de esta funcionalidad, previamente se ha de comprender en que situaciones podemos hacer uso de ella y qué tipos de acciones estan disponibles. Por ello, se detallan algunas de las acciones realizadas mediante las APIs:
Comprobar nuevos endpoints según la siguiente página de Rebranding
¶ Keystone (RBAC)
En esta sección, se pueden realizar acciones como las sigueintes:
- Autenticación y gestión de credenciales (obtención de tokens, creación y administración de accesos).
- Gestión de dominios y proyectos (visualización, administración y organización).
- Usuarios, roles y políticas (definición, interacción y control de permisos).
Puede comprobar las sigueintes documentaciones sobre Keystone API:
¶ Neutron (Conectividad)
En esta sección se pueden gestionar diferentes recursos:
- Redes e infraestructura (gestión de redes, subredes, puertos, trunks VLAN, routers, BGP, peers, VPNs, pools, IPs flotantes y redirecciones).
- Seguridad y control (grupos de seguridad, reglas, políticas de firewall, RBAC y QoS).
- Recursos y monitoreo (sabores, quotas, logs y visualización de reglas QoS).
Puede comprobar las sigueintes documentaciones sobre Neutron API:
¶ Nova (Computación)
En esta sección se pueden revisar diferentes acciones:
- Infraestructura y recursos (agregados de host, hipervisores, sabores y quotas).
- Gestión de servidores y acceso (detalles de servidores y pares de claves).
Puede comprobar las sigueintes documentaciones sobre Nova API:
¶ Cinder (Almacenamiento)
En esta sección se pueden revisar diferentes acciones:
- Almacenamiento y copias (volúmenes, snapshots y backups).
- Configuración y control (tipos de volúmenes, quotas y QoS).
Puede comprobar las sigueintes documentaciones sobre Cinder API:
¶ Visualizar API Rest en el orquestador
Comprobar nuevos endpoints según la siguiente página de Rebranding
En el orquestador existe una sección donde se muestra el listado de endpoints disponibles y la documentación asociada a cada API Rest separado por módulos, facilitando su exploración y utilización.
Para poder visualizar el listado de modulos, con sus respectivos endpoints y documentaciones desde el orquestador, debemos pulsar sobre el nombre de nuestro usuario en la esquina superior derecha de la ventana y seleccionar la opciónd de API REST.
Una vez realizado este procedimiento, podremos ver todas la información sobre enlaces de interés tanto de modulos internos de Openstack como de otros servicios de AireCloud como BaaS Premium (Commvault) o la plataforma de Tickets para consultas o incidencias.
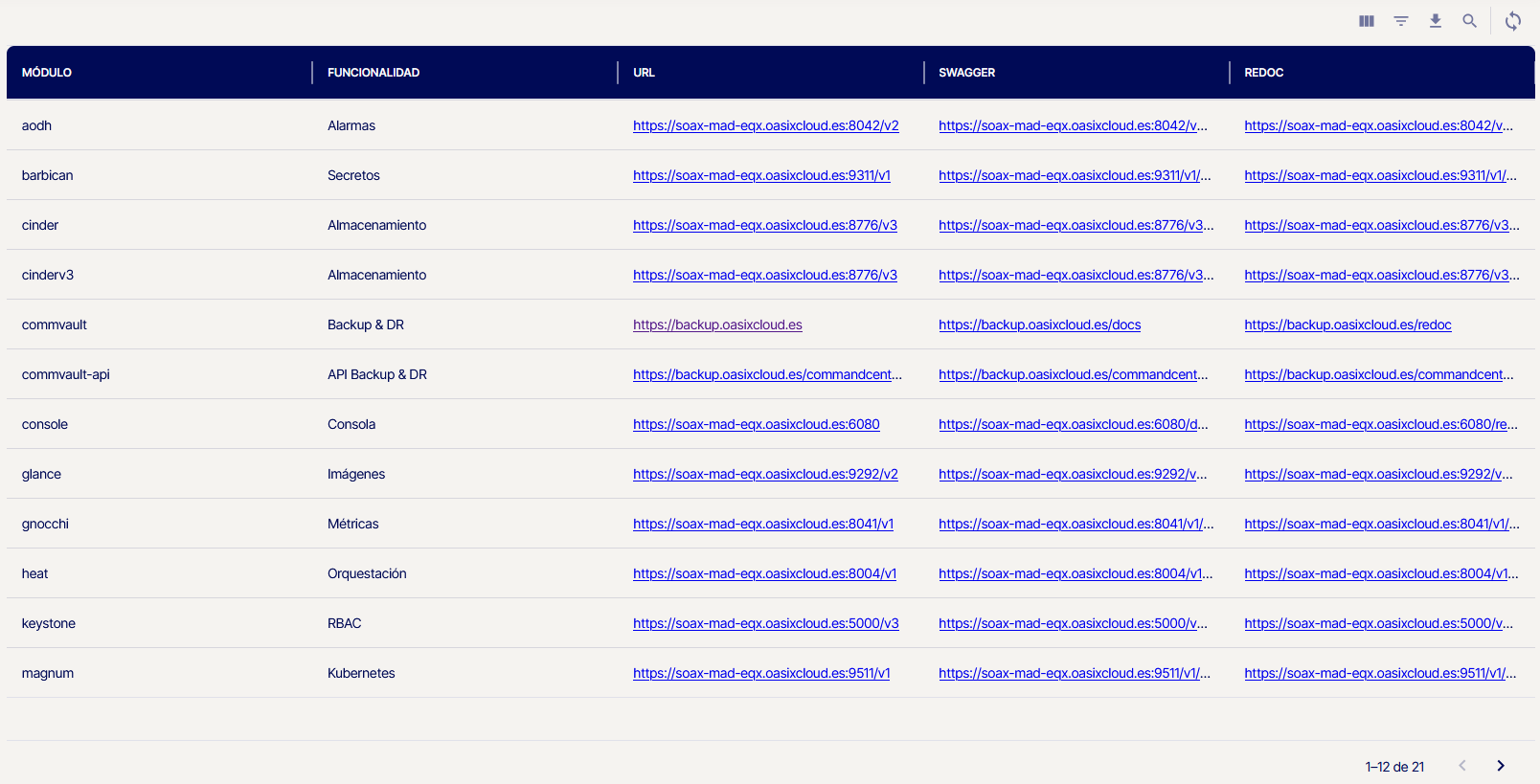
Dependiendo en la región que nos encontremos, se mostrarán los endpoints de su respectiva región.
¶ Visualizar Token de sesión en el orquestador
Para obtener el token de inicio de sesión para el uso de las API desde el orquestador, tendremos que seleccionar en la parte superior derecha de la pantalla nuestro nombre y hacer clic para lanzar el desplegable:

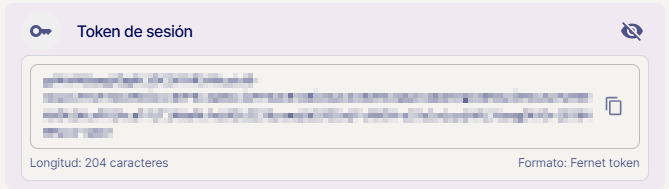
Una vez desplegadas las opciones, seleccionaremos la opción Identidad. Una vez accedemos al apartado de identidad podremos observar distintos datos de nuestro usuario actual, pero nos centraremos en el recuadro que especifica "Token" y haremos clic en el ojo para así visualizar nuestro Token de usuario para su uso en APIs.
De esta manera ya tendremos nuestro Token de usuario listo para copiar y usarlo en nuestro entorno de conexión para las APIs:
¶ Casos de uso
El acceso mediante API en la nube pública de Aire Cloud ofrece a los clientes una forma flexible y automatizada de interactuar con sus entornos y recursos. Las APIs del orquestador permiten integrar la gestión de la infraestructura directamente en aplicaciones, pipelines o sistemas, facilitando la automatización, la eficiencia y la escalabilidad. Esto habilita múltiples escenarios prácticos como los siguientes:
- Automatización de despliegues: creación de servidores, redes y volúmenes sin intervención manual.
- Integración con CI/CD: provisión y destrucción de entornos de prueba o producción desde pipelines.
- Escalado dinámico: ajuste de recursos en función de la demanda.
- Gestión de redes: configuración de VPNs, reglas de seguridad, balanceadores e IPs flotantes.
- Optimización de costos: consulta de consumos y liberación de recursos no utilizados.
- Autoservicio de usuarios: gestión de proyectos y credenciales bajo políticas definidas.
- Respaldo y recuperación: snapshots y backups programados para garantizar continuidad de negocio.
- Cumplimiento y auditoría: acceso a logs, trazas y aplicación de políticas de seguridad.
¶ Ejemplos
En este caso, utilizaremos una api específica para obtener un token de autenticación.
Se pueden utilizar diferentes métodos de autenticación como los siguientes:
- Autenticación Multi-Step (ejemplo con 2 factores: contraseña y TOTP)
- Autenticación con un Application Credentials.
En este caso, se va a explicar cómo realizar la autenticación via API usando la primera opción.
Puede consultar toda la información sobre Application Credentials en el siguiente enlace:
- Método / URL
POST {{platform_url}}/auth/tokens
- Petición
A continuación, se muestran todos los parámentros relacionados con esta acción.
| NAME | In | Type | Descripción |
|---|---|---|---|
| nocatalog (Opcional) | query | string | La respuesta de autenticación excluye el catálogo de servicios. Por defecto, la respuesta incluye el catálogo de servicios. |
| auth | body | object | Un objeto de autenticación. |
| identity | body | object | Un objeto de identidad. Debe estar contenido en el objeto auth. |
| methods | body | array | Los métodos de autenticación. Para autenticación por contraseña, especificar "password". Para autenticación TOTP, especificar "totp". En esta solicitud, ambos métodos deben ser especificados. |
| totp | body | object | Un objeto totp. Debe estar contenido en el objeto identity. Contiene los parámetros TOTP necesarios para realizar esta solicitud. |
| password | body | object | El objeto password, contiene la información de autenticación. Debe estar contenido en el objeto identity. |
| user | body | object | Un objeto user. Debe estar contenido en los objetos totp y password. |
| user.id (Opcional) | body | string | El ID del usuario. Requerido si no se especifica el nombre de usuario. |
| user.name (Opcional) | body | string | El nombre del usuario. Requerido si no se especifica el ID del usuario. |
| user.passcode | body | string | El código para validar la solicitud TOTP. |
| user.password | body | string | La contraseña para autenticar la solicitud del usuario. |
| scope | body | object | Un objeto scope. Debe estar contenido en el objeto auth. Contiene el alcance (proyecto, dominio,...) de la solicitud. |
| scope.id | body | string | El ID de la entidad según el scope (proyecto, dominio,...). |
- Ejemplo
Para realizar la petición utilizamos:
https://{{platform_URL}}/auth/tokens
Indicando un body como el siguiente:
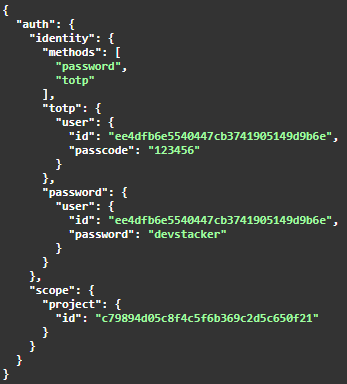
Como respuesta se obtiene el token en la cabecera y los sigueintes detalles como body:
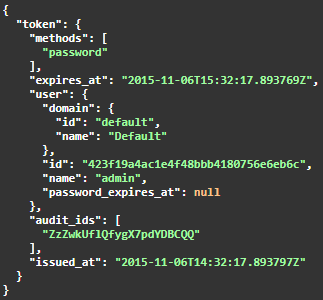
Una vez se obtiene el token, se podrá utilizar para autenticar al realizar el resto de llamadas de API en el orquestador.
En este caso, utilizaremos una api específica para obtener las trazas (de acción o de seguridad) del orquestador.
En este caso, se pueden incluir diferentes parámetros para filtrar la obtención de trazas. Si no se filtra (ningún parámetro especificado), se obtienen las trazas de acción del día actual, y todas las trazas que el rol del usuario permita visualizar.
- Método / URL
POST {{platform_url}}/Wotan/api/traces
- Petición
Todos los parámetros para esta petición son opcionales menos el token para realizar la autenticación.
| NAME | In | Type | Description |
|---|---|---|---|
| token * | header | string | A valid OpenStack token |
| domain | URL | string | Domain name requested to get its traces |
| project | URL | string | Project name requested to get its traces |
| user | URL | string | Username requested to get its traces |
| type | URL | string | Type of traces requested. If not specified, the default value is "action" |
| start_date | URL | string | Date from which traces are going to be obtained. If not specified, the default value is the current day |
| end_date | URL | string | Date up to which traces are going to be obtained. If not specified, the default value is the current day |
| contains | URL | string | A text that can be specified to filter the traces that have this text. Default is empty string |
- Ejemplo
Para realizar la petición utilizamos:
https://{{platform_URL}}/Wotan/api/traces?type=action&start_date=2022-11-02
Como respuesta se obtiene un contenido similar al siguiente:
| NAME | In | Type | Description |
|---|---|---|---|
| traces | body | string | Traces according to given parameters |

En este caso, utilizaremos una API concreta para listar instancias y sus detalles.
- Método / URL
GET {{platform_url}}/api/servers
- A continuación, se muestran todos los parámentros relacionados con esta acción.
| NAME | In | Type | Descripción |
|---|---|---|---|
| access_ip_v4 (Opcional) | query | string | Filtra por la IPv4 por la que se puede acceder al servidor. |
| access_ip_v6 (Opcional) | query | string | Filtra por la IPv6 por la que se puede acceder al servidor. |
| all_tenants (Opcional) | query | boolean | Especifica el parámetro de consulta all_tenants para listar todas las instancias de todos los proyectos. Por defecto, esto solo está permitido para los administradores. Si este parámetro se especifica sin valor, el valor predeterminado es True. Si se especifica un valor, los siguientes: 1, t, true, on, y, yes se interpretan como True. Y los siguientes: 0, f, false, off, n, no se interpretan como False. (Todos son insensibles a mayúsculas y minúsculas).. |
| auto_disk_config (Optional) | query | string | Filtra el resultado de la lista de servidores por la configuración disk_config del servidor. Los valores válidos son: AUTO y MANUAL. Este parámetro solo es válido cuando lo especifican administradores. Si los usuarios que no son administradores especifican este parámetro, se ignora. |
| availability_zone (Optional) | query | string | Filtra el resultado de la lista de servidores por la zona de disponibilidad del servidor. |
| changes-since (Optional) | query | string | Filtra la respuesta por una marca de fecha y hora correspondiente a la última vez que el servidor cambió de estado. |
| config_drive (Optional) | query | string | Filtra el resultado de la lista de servidores por la configuración config drive del servidor. |
| created_at | body | string | Filtra el resultado de la lista de servidores por una marca de fecha y hora correspondiente a cuando el servidor fue creado. |
| deleted (Optional) | query | boolean | Muestra solo los elementos eliminados. En algunas circunstancias, los elementos eliminados seguirán siendo accesibles a través de la base de datos del backend; sin embargo, no existe ninguna garantía sobre cuánto tiempo, por lo que este parámetro debe usarse con precaución. Los valores 1, t, true, on, y y yes se interpretan como True (no distinguen mayúsculas/minúsculas). Cualquier otro valor se interpreta como False. |
| description (Optional) | query | string | Filtra el resultado de la lista de servidores por la descripción. |
| flavor (Optional) | query | string | Filtra la respuesta por un flavor, usando su UUID. Un flavor es una combinación de memoria, tamaño de disco y CPUs. |
| host (Optional) | query | string | Filtra el resultado de la lista de servidores por el nombre de host del nodo de cómputo. |
| hostname (Optional) | query | string | Filtra el resultado de la lista de servidores por el nombre de host del servidor. |
| image (Optional) | query | string | Filtra la respuesta por una imagen, utilizando su UUID. |
| ip (Optional) | query | string | Una dirección IPv4 por la que filtrar los resultados. |
| ip6 (Optional) | query | string | Una dirección IPv6 por la que filtrar los resultados. |
| kernel_id (Optional) | query | string | Filtra el resultado de la lista de servidores por el UUID de la imagen del kernel cuando se utiliza un AMI. |
| key_name (Optional) | query | string | Filtra el resultado de la lista de servidores por el nombre de host del servidor. |
| launch_index (Optional) | query | integer | Filtra el resultado de la lista de servidores por la secuencia en la que fueron lanzados. |
| launched_at (Optional) | query | string | Filtra el resultado de la lista de servidores por una marca de fecha y hora correspondiente al momento en que la instancia fue lanzada. |
| limit (Optional) | query | integer | Solicita un tamaño de página de elementos. Devuelve un número de elementos hasta un valor límite. Utiliza el parámetro limit para hacer una primera solicitud limitada y usa el ID del último elemento visto en la respuesta como valor del parámetro marker en una solicitud limitada posterior. |
| locked_by (Optional) | query | string | Filtra el resultado de la lista de servidores por quién bloqueó el servidor; los valores posibles pueden ser admin u owner. |
| marker (Optional) | query | string | El ID del último elemento visto. Utiliza el parámetro limit para hacer una primera solicitud limitada y usa el ID del último elemento visto en la respuesta como valor del parámetro marker en una solicitud limitada posterior. |
| name (Optional) | query | string | Filtra la respuesta por un nombre de servidor, como una cadena de texto. Puedes usar expresiones regulares en la consulta. Por ejemplo, la expresión regular ?name=bob devuelve tanto bob como bobb. Si necesitas que coincida solo con bob, puedes usar una expresión regular que coincida con la sintaxis del servidor de base de datos subyacente usado por Compute, como MySQL o PostgreSQL. |
| node (Optional) | query | string | Filtra el resultado de la lista de servidores por el nodo. |
| power_state (Optional) | query | integer | Filtra el resultado de la lista de servidores por el estado de energía (power state) del servidor. Los valores posibles son valores enteros, que se asignan de la siguiente forma: 0: NOSTATE | 1: RUNNING | 3: PAUSED | 4: SHUTDOWN | 6: CRASHED | 7: SUSPENDED |
| progress (Optional) | query | integer | Filtra el resultado de la lista de servidores por el progreso del servidor. El valor puede estar entre 0 y 100, como un número entero. |
| project_id (Optional) | query | string | Filter the list of servers by the given project ID. This filter only works when the all_tenants filter is also specified. |
| ramdisk_id (Optional) | query | string | Filtra el resultado de la lista de servidores por el UUID de la imagen ramdisk cuando se utiliza un AMI. |
| reservation_id (Optional) | query | string | Un ID de reserva tal como es devuelto por una llamada de creación múltiple de servidores. |
| root_device_name (Optional) | query | string | Filtra el resultado de la lista de servidores por el nombre del dispositivo raíz (root device) del servidor. |
| soft_deleted (Optional) | query | boolean | Filtra la lista de servidores por el estado SOFT_DELETED. Este parámetro solo es válido cuando el parámetro de filtro deleted=True está especificado. |
| sort_dir (Optional) | query | string | Dirección de ordenación. Un valor válido es asc (ascendente) o desc (descendente). El valor predeterminado es desc. Puedes especificar múltiples pares de parámetros de consulta: sort key y sort direction. |
| sort_key (Optional) | query | string | Ordena por un atributo del servidor. El atributo predeterminado es created_at. Puedes especificar múltiples pares de parámetros de consulta: sort key y sort direction. Si omites la dirección de ordenación en un par, la API utiliza la dirección de ordenación natural del atributo sort_key del servidor. |
| status (Optional) | query | string | Filtra la respuesta por un estado del servidor, utilizando una cadena de texto. Por ejemplo: ACTIVE. |
| task_state (Optional) | query | string | Filtra el resultado de la lista de servidores por el estado de la tarea (task state). |
| terminated_at (Optional) | query | string | Filtra el resultado de la lista de servidores por una marca de fecha y hora correspondiente al momento en que la instancia fue terminada. |
| user_id (Optional) | query | string | Filtra la lista de servidores por el ID de usuario proporcionado. |
| uuid (Optional) | query | string | Filtra el resultado de la lista de servidores por el UUID del servidor. |
| vm_state (Optional) | query | string | Filtra el resultado de la lista de servidores por el estado de la máquina virtual (vm state). |
| not-tags (Optional) | query | string | Una lista de etiquetas por las que filtrar la lista de servidores. Se devolverán los servidores que no coincidan con todas las etiquetas de esta lista. La expresión booleana en este caso es: NOT (t1 AND t2). Las etiquetas en la consulta deben estar separadas por comas. |
| tags-any (Optional) | query | string | Una lista de etiquetas por las que filtrar la lista de servidores. Se devolverán los servidores que coincidan con cualquiera de las etiquetas de esta lista. La expresión booleana en este caso es: t1 OR t2. Las etiquetas en la consulta deben estar separadas por comas. |
| changes-before (Optional) | query | string | Filtra la respuesta por una marca de fecha y hora correspondiente a la última vez que el servidor cambió. Se devolverán aquellos servidores que cambiaron antes o en la fecha y hora especificadas. Para ayudar a realizar un seguimiento de los cambios, esto también puede devolver servidores que hayan sido eliminados recientemente. |
| locked (Optional) | query | boolean | Especifica el parámetro de consulta locked para listar todas las instancias bloqueadas o desbloqueadas. Si se especifica un valor, los siguientes se interpretan como True (no distinguen mayúsculas/minúsculas): 1, t, true, on, y, yes. Los siguientes se interpretan como False: 0, f, false, off, n, no. Cualquier otro valor proporcionado se considerará inválido. |
- Ejemplo
Para realizar la petición utilizamos:
https://{{platform_URL}}/api/servers
Como respuesta se obtienen las instancias que tengamos:

- Caso extra
Si queremos más detalles,con la posibilidad de usar los mismos parametros que antes, podemos realizar la petición desde:
https://{{platform_URL}}/api/servers/detail
- Ejemplo con curl

Dando como resultado la siguiente respuesta:
En este caso, utilizaremos una API concreta para aparcar una instancia y luego desaparcarla.
- Método / URL
GET {{platform_url}}/api/servers/{server_id}/action
A continuación, se añade al body lo siguiente:
{
"shelve": null
}
- Ejemplo curl

Y para desaparcarla, en su lugar añadiríamos:
{
"unshelve": null
}
Estas acciones podrán verse reflejadas en el orquestador.
En este caso, utilizaremos una API concreta para listar las meterings y sus detalles.
- Método / URL
GET {{platform_url}}/api/meterings
- Petición
A continuación, se muestran todos los parámentros relacionados con esta acción.
| NAME | In | Type | Descripción |
|---|---|---|---|
| domain_id | path | string | Introduciremos el ID del dominio al que pertenece el proyecto. |
| project_id | path | object | ID del proyecto sobre el que queremos obtener las meterings |
| region | query | object | Región donde se encuentra el proyecto. |
| start_date | query | array | Inicio de la fecha desde donde queramos obtener la información. |
| end_date | query | object | Valor de la fecha hasta la que se quiere obtener la información. |
| page | query | object | La página que queremos que nos muestre de todas las obtenidas en los resultados. |
| size | query | object | El número de elementos que queremos que nos muestre por página. |
| X-Auth-Token | header | string | El token del usuario generado. |
- Ejemplo
Para realizar la petición utilizamos:
https://{{platform_URL}}/api/meterings/domains
Indicando una petición como la siguiente:
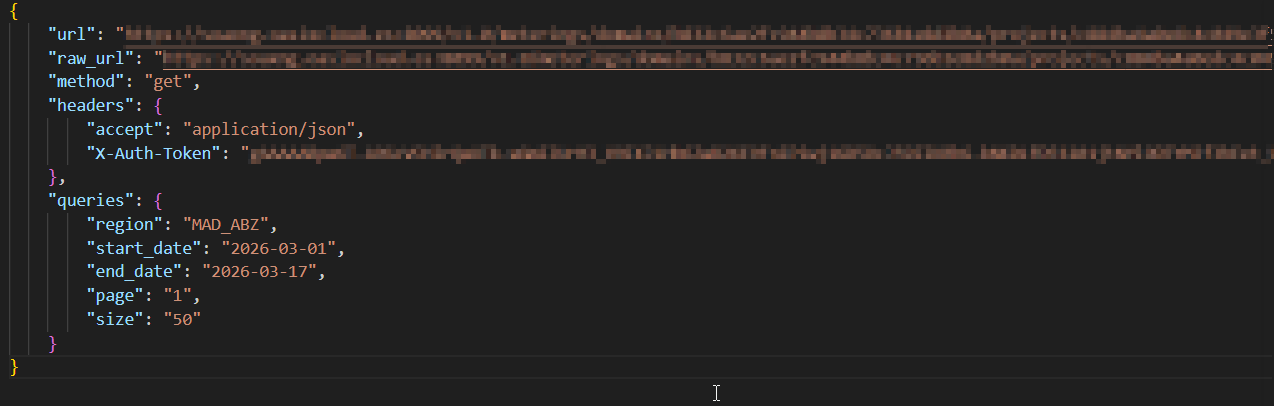
Como respuesta se obtiene una lista con todos las metricas del proyecto:
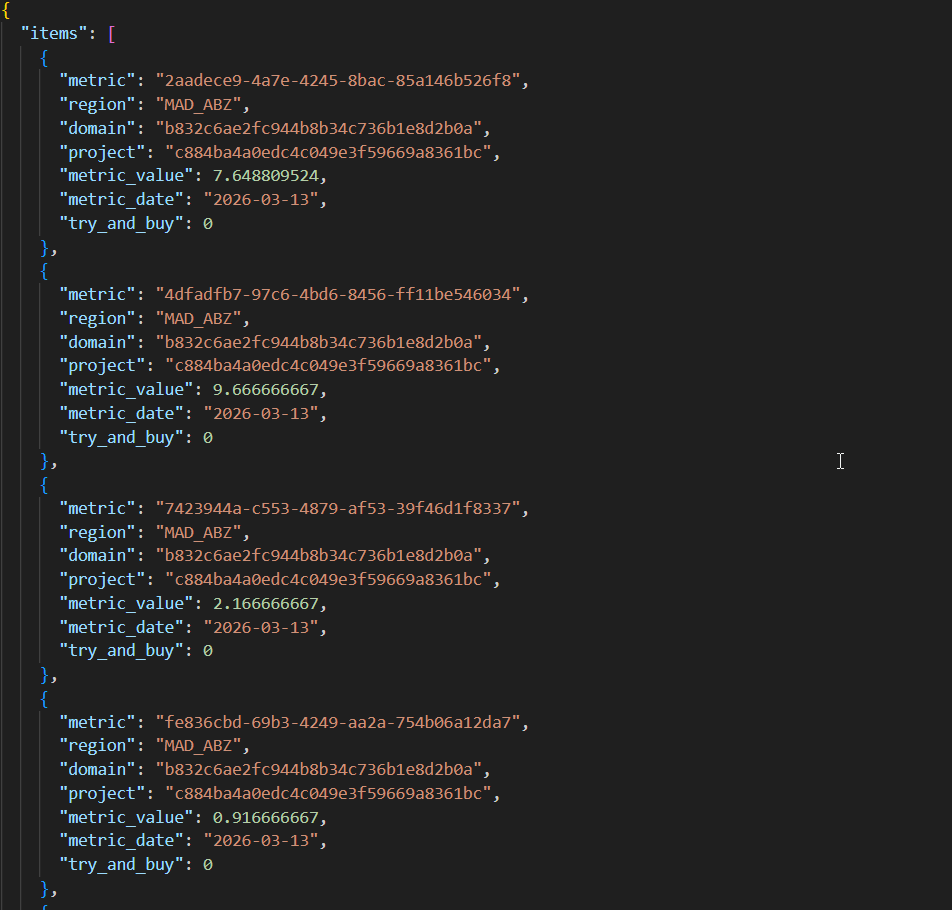
Por defecto la API lista 50 elementos por página, si queremos otra cantidad de elementos habrá que modificarla.
En este caso, utilizaremos una API para poder recuperar metricas guardadas mediante Monitorización.
- Método / URL
GET {{platform_url}}/api/aggregates
- Petición
A continuación, se muestran todos los parámentros relacionados con esta acción.
| NAME | In | Type | Descripción |
|---|---|---|---|
| fill | query | string |
Cubre los huecos de medida si se van a realizar medidas cada cierto tiempo. Posibilidades: 1. float Rellena los huecos con un número específico que tú definas (por ejemplo, poner siempre 0 donde no haya datos) 2. Elimina los puntos faltantes de la respuesta. La serie de datos simplemente se salta esos periodos de tiempo en lugar de mostrar un valor. 3. null: Mantiene el hueco indicando explícitamente que el valor es nulo. En las gráficas, esto suele verse como una línea cortada. 4. ffill (Forward Fill): Rellena el hueco con el último valor conocido. Si a las 10:00 el valor era 50 y a las 10:01 no hay datos, le asigna 50. 5. bfill (Backward Fill): Rellena el hueco con el siguiente valor disponible. Mira hacia el futuro y copia ese valor hacia atrás. 6. full_ffill: Similar a ffill, pero se asegura de propagar el último valor conocido a través de todo el rango de la consulta, incluso si el hueco es muy largo. 7. full_bfill: Similar a bfill, pero rellena hacia atrás en todo el rango solicitado desde el primer valor que encuentre. |
| granularity | query | string | Es el valor que define cada cuánto recibiremos un resumen de los datos solicitados. |
| start | query | date | Fecha en la que queremos que se inicie la recopilación de datos. |
| stop | query | date | Fecha en la que queremos que acabe la recopilación de datos. |
| needed_overlap | query | string | Porcentaje con el que queremos que se cumpla la petición. |
| groupby | query | object | Permite agrupar y separar los resultados obtenidos. |
| use_history | query | boolean | Si lo activamos, tomará valores antiguos a la hora de obtener resultados. |
- Ejemplo
Para realizar la petición utilizamos:
https://{{platform_URL}}/api/aggregates
Indicando una petición como la siguiente:
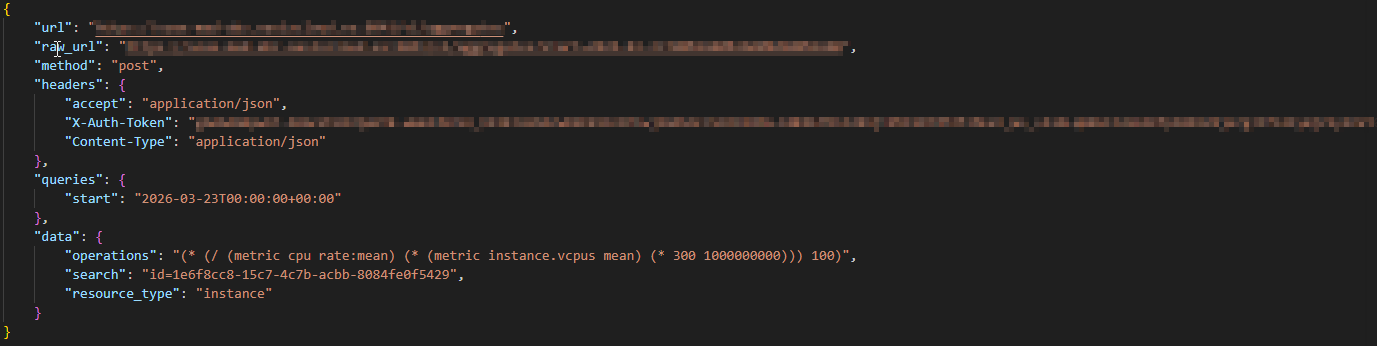
Como respuesta se obtiene las métricas solicitadas en la petición, en nuestro caso las de una CPU de una instancia en concreto:
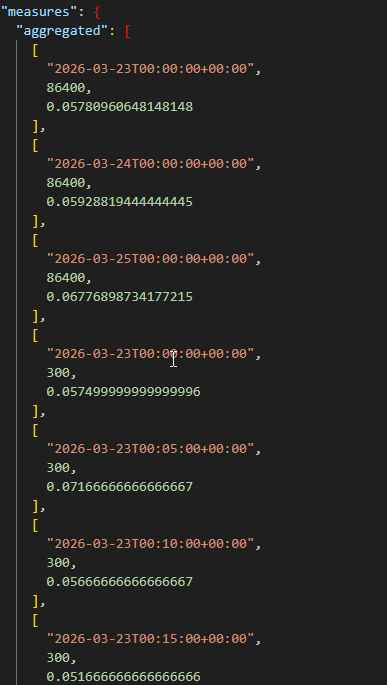
Nota: Es posible la instalación de un agente externo en caso de querer real time.
Inicialización a las APIs de orquestador
como usar las APIs de orquestador
API orquestador
Como consultar la API de orquestador